Overview |
The Report Miner processing engine can be described as in the following diagram.
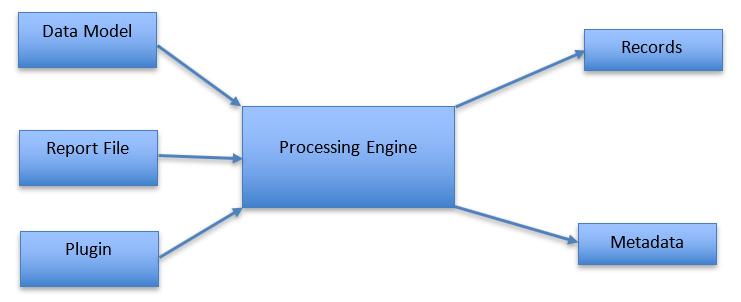
Data Model is normally created by using the Report Miner graphical designer. You simply draw boxes on a sample report file and annotate them as labels, fields, tables and other data elements. The processing engine requires the path to a Data Model file as an input parameter. Data Model file are in XML format.
Report File is the path to a specific report file that you wish to process against the data model. If you don’t specify this input, the sample file that was used to design the data model will be processed.
Plugin is the name of user-defined DLL file that implements the API IPlugin interface as described later in this document. The Plugin is optional.
Processing Engine is the central unit of the report miner responsible for identification, classification, matching and extraction of data elements and logical records within the report file.
Records is the set of logical records extracted from the report file. You may think of a record as a complete document that was embedded in the report file. In other words, a report file may consist of several individual documents. For instance, a report file of bank statements may contain thousands of individual statements, each representing a separate account. A statement within such report is considered a logical record and may be extracted as a separate PDF document. A report file may also be treated as a single record. In this case, the report file will not be split.
Metadata is the set of all data, including labels, fields and tables, that is extracted from a logical record within a report file.